
大模型技术基础
大模型的构建预览
定义:通常是指具有超大规模参数的预训练语言模型
架构:主要为Transformer解码器架构
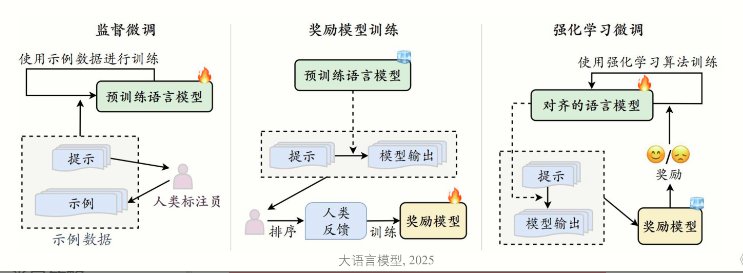
训练:主要分为预训练(base model) 后训练(instruct model)
1 | graph TB |
预训练:使用与下游任务无关的大规模数据进行模型参数的初始训练。基于transformer解码器架构,进行下一个词预测。数据数量和质量都非常关键。
后训练:又分为两种:指令微调和人类对齐
- 指令微调:使用输入与输出配对的指令数据对于模型进行微调,提升模型通过问答形式进行任务求解的能力。
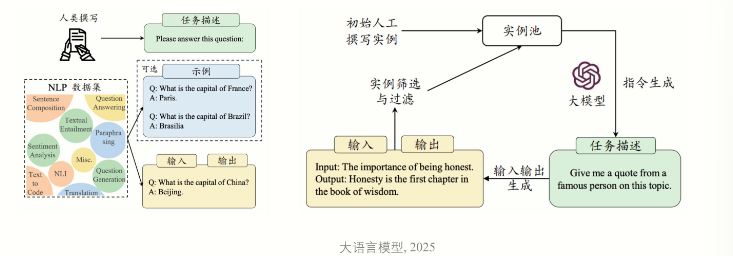
- 人类对齐:将大语言模型与人类的期望、需求以及价值观对齐;基于人类反馈的强化学习方法 (RLHF)
扩展定律基础概念
扩展定律(Scaling Law)揭示了语言模型性能与模型规模、数据量及计算资源之间的数学关系,其核心是幂律法则(Power Law)。随着模型参数量(N)、训练数据量(D)和计算量(C)的增加,模型损失(Loss)呈现指数级下降,但边际效益逐渐递减。
通过扩展参数规模、数据规模和计算能力,大语言模型的能力会出现显著提升,扩展定律在本次大模型浪潮中起到了重要作用。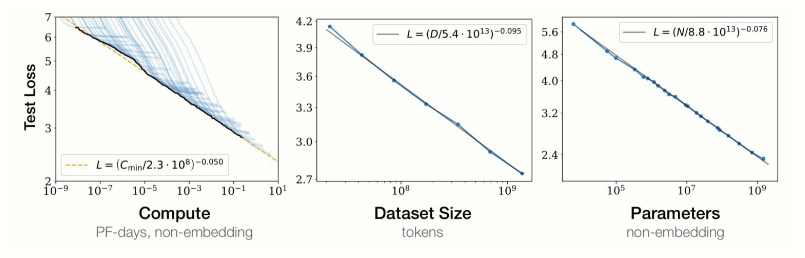
核心公式:
$L(N,D)=L_0+k⋅N^{−α}+m⋅D^{−β}$
- L0:数据固有噪声带来的不可约损失
- α 和 β:参数和数据对损失的衰减系数(通常 α≈0.07, β≈0.27)
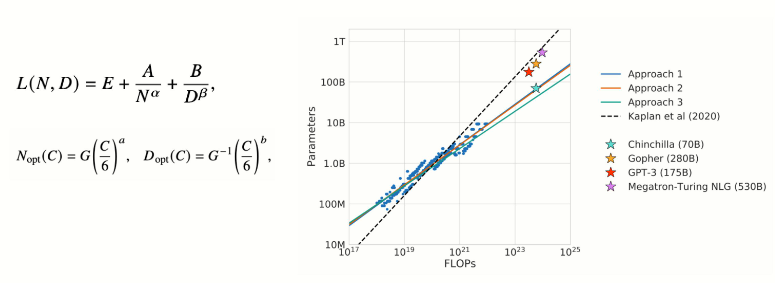
KM扩展定律与Chinchilla扩展定律对比
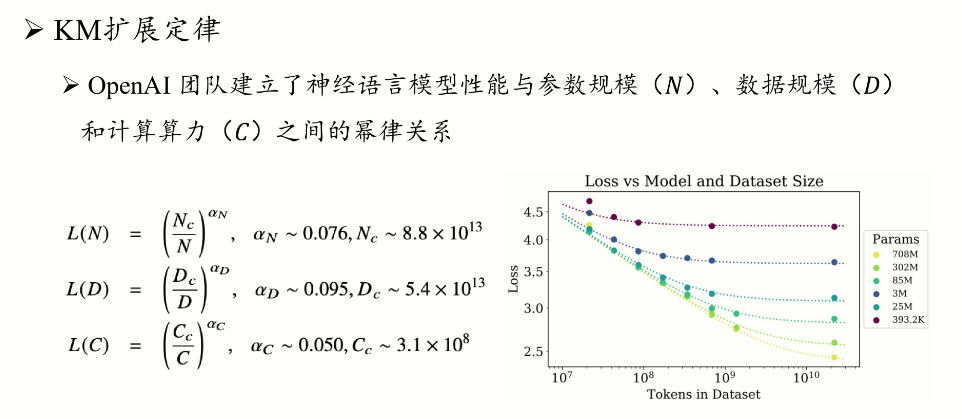
KM扩展定律(OpenAI, 2020)
- 核心发现:在计算预算约束下,优先扩大模型参数(N)而非数据量(D),参数增长比数据扩展更有效。
- 公式推导:$L(N)∝N^{−0.07},L(D)∝D^{−0.27}$
- 应用场景:早期大模型(如GPT-3)通过堆叠参数(175B参数+300B tokens)实现突破,但存在数据饥饿风险。
Chinchilla扩展定律(DeepMind, 2022)
DeepMind团队再2022年提出了另一种形式的扩展定律,旨在指导大模型充分利用给定的算力资源优化训练。
- 核心修正:模型参数与数据需同步扩展,最佳比例为 D≈20N(如70B参数模型需1.4T tokens)。
- 关键突破:
- Chinchilla(70B参数+1.4T tokens)性能超越GPT-3(175B参数+300B tokens)。
- 计算资源分配更高效,训练成本降低30%。
- 现实意义:纠正了盲目扩大参数的趋势,推动模型小型化与高效训练。
扩展定律可能存在边际效益递减 :随着模型参数、数据数量的扩展,模型性能增益将逐渐减小。目前开放数据已经接近枯竭,难以支持扩展定律持续推进。
可预测的扩展(Predictable Scaling)
可预测的扩展是通过扩展定律提前估算模型性能的技术,避免大规模试错成本。其实现路径包括:
数学建模与对数线性回归
- 使用小规模实验(如7B参数模型)预测大模型(65B)性能,误差可控制在2%以内。
- 案例:Meta Llama团队通过7B模型预测65B模型的困惑度(PPL)。
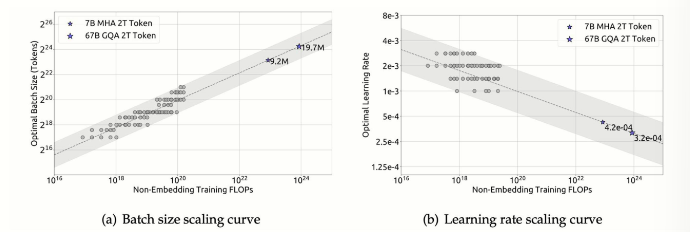
数据瓶颈的量化分析
- 当前公共高质量英文语料年增量仅3T tokens,接近饱和(利用率达98%),需依赖合成数据与多模态扩展。
- 应对策略:通过数据蒸馏(如DeepSeek使用GPT生成合成数据)突破数据瓶颈。
训练动态的可控性
- 临界模型规模:研究发现,将模型缩小至计算最优规模的30%,仅需增加100%计算量即可维持性能,为小型化提供理论依据。
- 超参数预测:学习率与训练步长的动态调整公式(如 $LR=0.003−0.0002⋅log_{10}(N)$)。
扩展定律的实践启示
- 资源分配:根据任务需求选择扩展策略——KM适合快速突破,Chinchilla适合长期优化。
- 成本控制:通过可预测扩展估算最小可行模型规模,避免算力浪费(如LLaMA-7B在1T tokens训练后仍有优化空间)。
- 技术融合:结合强化学习(RLHF)与多模态扩展,突破单一扩展维度限制(如GPT-4V的图文推理能力)。
涌现能力
涌现能力(Emergent Abilities)是指当大规模语言模型(如GPT-3、BERT等)的参数规模达到一定阈值后,模型在没有明确训练或设计的情况下,自发地展现出一些高级或复杂的技能或行为。这些能力不是直接编程或显式训练的结果,而是模型通过学习大量数据并在内部形成复杂的表示和结构后自然而然地出现的。“小模型中不存在,但在大模型中出现的能力”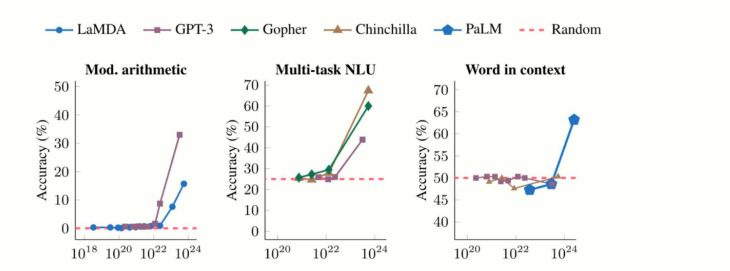
涌现能力的特点
- 非显式训练:模型并未针对特定任务进行专门训练,却能执行这些任务。例如,语言模型可能在没有接受翻译训练的情况下生成准确的翻译文本。
- 复杂性和多模态性:涌现能力涉及多层次的抽象和多种类型的数据处理,如语言理解、逻辑推理、数学计算等。
- 自适应性:模型能够根据上下文和任务需求灵活调整行为,例如对话系统在不同场景下进行适当回应。
代表性能力的种类
- 上下文学习(In-Context Learning):模型通过少量示例(demonstrations)快速适应新任务,无需额外训练。例如,GPT-3仅通过几个示例就能完成翻译、总结等任务。
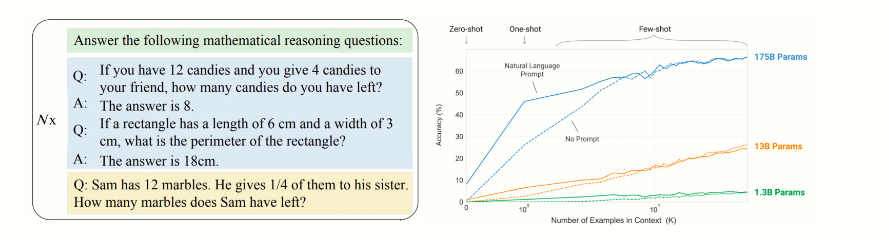
- 进步推理(Chain of Thought Reasoning):模型能够进行多步逻辑推理,解决复杂的数学或逻辑问题。例如,通过“思维链提示”(Chain of Thought Prompting)策略,模型逐步推理出答案。
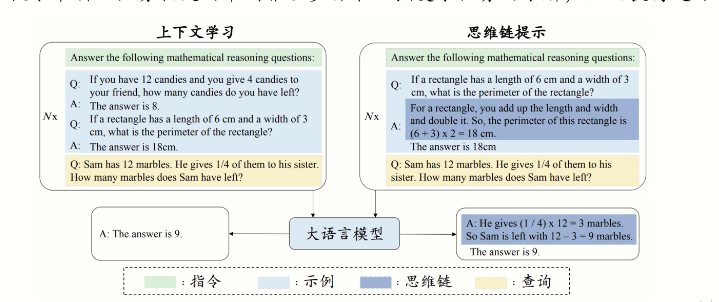
- 指令遵循(Instruction Following):模型能够理解并执行复杂的指令,例如根据用户指令生成特定格式的文本或完成特定任务。
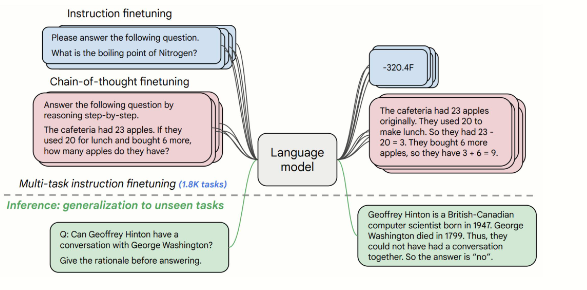
涌现能力与扩展定律的关系
扩展定律(Scaling Law)揭示了模型性能与模型规模(参数数量N)、数据量(D)和计算量(C)之间的幂律关系。随着模型规模的增加,性能呈指数级提升,但涌现能力在达到某一临界规模后突然出现,无法通过小规模模型的性能外推预测。
具体来说:
- 规模效应:当模型参数规模超过某一阈值(如数十亿参数),涌现能力会突然显现。例如,GPT-3在175B参数规模下展现出上下文学习和进步推理能力。
- 非线性提升:涌现能力的出现与模型规模的增加呈非线性关系,表现为“相变”现象:在临界规模之前,性能接近随机;超过临界规模后,性能显著提升。
- 扩展定律的局限性:扩展定律可以预测模型性能的平滑提升,但无法预测涌现能力的出现,因为涌现能力是模型规模、数据量和计算量综合作用的结果。
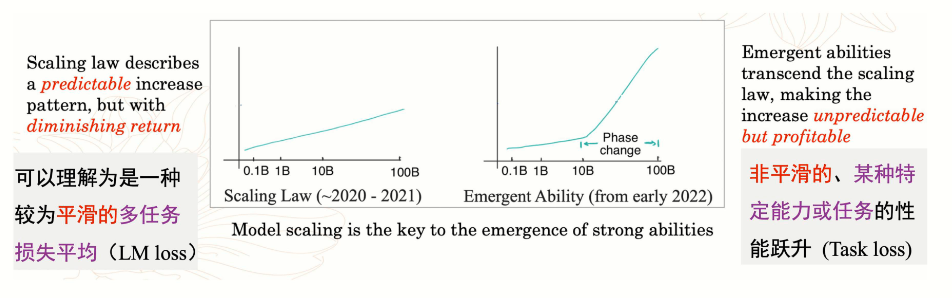
总结来说,涌现能力是大规模语言模型在达到一定规模后展现出的高级能力,其出现与扩展定律密切相关,但具有不可预测性和非线性特征。
 wechat
wechat alipay
alipay



